Jeudi, 23 février 2023
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I run my own instance of Mastodon on a
server with little memory, i.e. not enough to be able to run ElasticSearch in
addition to Mastodon. This means that I cannot do a full-text search on my
toots (which would have come handy from time to time).
As an alternative solution, I have implemented a full-text search on database.
It is most probably not suitable to use on a large instance, as the
implementation uses an SQL query with multiple LIKE conditions ORed together.
That's not the most efficient way of querying a database, but for a small
enough number of statuses (40k at the moment), it's probably good enough.
This feature is (and will probably forever remain) experimental, but if you
want to give it a try, and assuming that you have installed Mastodon from
Git like me
in /home/mastodon/live and run v4.1.0, here's how to do it.
As user
mastodon, run:
$ cd /home/mastodon/live
$ git remote add db_search https://weber.fi.eu.org/software/mastodon
$ git fetch db_search
$ git checkout v4.1.0+db_search.1
$ echo "FULL_TEXT_DB_SEARCH=true" >> .env.production
Then restart the
mastodon-web service by running as root:
systemctl restart mastodon-web.service
Reload the mastodon Web UI in your web browser. When you click on the search
box, you should now see a message like “Simple text returns posts you have
written…” and searching with words you know you have written should display
matching toots.
EDIT: I expanded the search to also consider the descriptions of
media attachments. The updated version is available as tag v4.1.0+db_search.1.
[ Posté le 23 février 2023 à 14:56 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/full-text_search_in_database_for_mastodon.trackback
Commentaires
Aucun commentaire
Mercredi, 20 avril 2022
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
There was Mastermind_(board_game) where you have to guess the
correct colors in the correct order. Then came Wordle, where you have to guess
the correct letters in the correct order to make an actual word. And then came
Nerdle where you have to guess the correct
arithmetic identity, using digits from 0 to 9, the four usual operations and
the “equal” sign.
That was fun the couple of first times, but then came the itch to write a
solver for it (like I did a long
time ago with the Sudoku: same kind of repetitive puzzle, same geek reflex).
$ python3 nerdle.py
([c]orrect [i]ncorrect [a]bsent
8+7*6=50 > iiaaaiai
10+2-4=8 > cccacaci
10+1-8=3 > cccccccc
10+1-8=3
The user interface is trivial: the solver prompts a solution, type it in the
Nerdle web interface, then type the colored hints back into the solver: green
is “c” for Correct, purple is “i” for Incorrect and black is “a” for
Absent (as indicated by the solver when you start it).
It always starts with the same first attempt, that is composed of 8 of the 15
possible symbols. Then based on the hints, it computes possible next
solutions and ranks them based on the diversity of the symbols it contains and
the amount of yet-unused ones (assuming that the actual solution contains as
wide a variety of symbols as possible, and that unused symbols need to be
tried).
One thing I liked when coding this little tool is that I got to use sets a
lot, and implement a lot of the logic using set operations.
[ Posté le 20 avril 2022 à 14:01 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/nerdle_solver.trackback
Commentaires
Aucun commentaire
Dimanche, 11 avril 2021
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Gmail started to complain recently that the messages forwarded by the trivial
mailing-list hosted on my server did not pass the ARC validation. As Google
already considers e-mail coming from my domain as spam (but strangely, not the
emails forwarded by the mailing list on the same domain), I did not want to risk
to see my e-mail treated as even less worthy to be delivered to the Valued
Customers of Gmail (i.e., probably half the world) than it is now. And I wanted
to look into ARC anyway. But the installation is not trivial, there are no
official Debian packages, and no clear tutorial on the Web, so here's what I
did. It may work for you or not.
This tutorial assumes you already have configured postfix with opendkim, and
they are running on a single computer on a Debian 10. The configuration example
expects postfix to run as chroot and uses the private key configured for
opendkim.
All the following commands need to be run as root or through sudo.
Install the package
Add an apt source by creating the file
/etc/apt/sources.list.d/openarc.list
and write:
deb https://download.opensuse.org/repositories/home%3A/andreasschulze/Debian_10 /
Then run:
curl https://download.opensuse.org/repositories/home:/andreasschulze/Debian_10/Release.key | apt-key add -
apt update
apt install openarc
If you don't want to run
curl as root, you can run that command instead:
curl https://download.opensuse.org/repositories/home:/andreasschulze/Debian_10/Release.key | sudo apt-key add -
This will install openarc 1.0.0 beta3-3, but the package's post-installation
script has a bug, so the installation fails. To fix it, edit
/var/lib/dpkg/info/openarc.postinst and comment-out line 62 which contains
ln -s ../../var/lib/supervise/openarc-milter /etc/service/
Then run as root apt install openarc again.
Configure OpenArc
Create /etc/openarc/keys and copy the key from opendkim (e.g.,
/etc/opendkim/keys/example.private) into /etc/openarc/keys/. Then copy
/etc/opendkim/TrustedHosts into /etc/openarc/.
Create /etc/openarc.conf (or create one such file based on
/usr/share/doc/openarc/openarc.conf.sample.gz) and modify the following
directives (without the quotes around the values, of course):
- AuthservID: the name of the server (e.g., “server.example.com”)
- Canonicalization: the value “relaxed/simple”
- Domain: the domain namd (e.g., “weber.fi.eu.org”)
- FinalReceiver: the value “no”
- InternalHosts: the value “/etc/openarc/TrustedHosts” (if there is a such a file)
- KeyFile: the path to the private key (e.g., “/etc/openarc/keys/example.private”)
- OversignHeaders: the value “From”
- PidFile: the value “/var/run/openarc.pid”
- Selector: the value of the opendkim selector (see Selector in opendkim.conf)
- Socket: the value “local:/var/spool/postfix/var/run/openarc/openarc.sock”
- Syslog: the value “Yes”
Create
/var/spool/postfix/var/run/openarc that will contain the socket:
mkdir /var/spool/postfix/var/run/openarc
chown openarc:openarc /var/spool/postfix/var/run/openarc
chmod 750 /var/spool/postfix/var/run/openarc
Add the postfix user to the openarc group so that postfix can access the socket
(run as root):
usermod -a -G openarc postfix
Create a systemd service file
/etc/systemd/system/openarc.service with the
following content:
[Unit]
Description=OpenARC Authenticated Received Chain (ARC) Milter
Documentation=man:openarc(8) man:openarc.conf(5) https://openarc.org/
After=network.target nss-lookup.target·
[Service]
Type=forking
PIDFile=/var/run/openarc.pid
UMask=0002
ExecStart=/usr/sbin/openarc -c /etc/openarc.conf
Restart=on-failure
[Install]
WantedBy=multi-user.target
The UMask directive is especially important, so that
/var/spool/postfix/var/run/openarc/openarc.sock is readable and writable by
the members of the openarc group (i.e., postfix). OpenDKIM has a UMask
directive, but OpenARC does not.
You can now start the service with
systemctl start openarc
Configure postfix
Edit
/etc/postfix/main.cf and add the socket to the
smtpd_milters and
non_smtpd_milters lists (you may already have other milters configured, such
as OpenDKIM):
smtpd_milters = unix:/var/run/opendkim/opendkim.sock,
unix:/var/run/openarc/openarc.sock
non_smtpd_milters = unix:/var/run/opendkim/opendkim.sock,
unix:/var/run/openarc/openarc.sock
Finally, restart postfix:
systemctl restart postfix
You can now test your OpenARC setup with the tools provided by
openarc.org.
[ Posté le 11 avril 2021 à 20:23 |
7
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/openarc_with_postfix_on_debian_10.trackback
Commentaires
Commentaire N° 1, MrPete (Peyton, United States)
le 12 décembre 2021 à 05:25
Update for Debian 11
Commentaire N° 2, Matthieu Weber (Kyröskoski, Finlande)
le 30 novembre 2022 à 10:58
Hello! You really got it working?
Commentaire N° 3, Tommy (Sweden)
le 18 janvier 2023 à 19:31
Commentaire N° 4, Matthieu Weber (Helsinki, Finlande)
le 18 janvier 2023 à 20:46
Signing works for you???
Commentaire N° 5, MrPete
le 24 mars 2023 à 03:22
Signing works for you???
Commentaire N° 6, MrPete
le 24 mars 2023 à 03:23
Mardi, 22 mai 2018
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
The Solarized color scheme redefines
some of the standard basic ANSI colors, making some color combinations
unsuitable for display. In particular, bright green, bright yellow, bright
blue and bright cyan are tones of grey instead of the expected colors.
Also, some terminals interpret bold text as bright colors, turning e.g, bold
green into a shade of grey instead of the expected green. At least in
URxvt, setting intensityStyles: False will prevent bold text from being
displayed in bright colors (but will still be displayed in a bold font).
When redefining color schemes for terminal applications using ANSI colors,
these are possible combinations, using the usual ANSI color names. Note that
bright colors are usually not available as background colors.
Solarized Light default background (ANSI white)
Normal:
black
red
green
yellow
blue
magenta
cyan
(light)grey
Bright:
black/grey
red
green
yellow
blue
magenta
cyan
white
ANSI (Light)Grey background
Normal:
black
red
green
yellow
blue
magenta
cyan
(light)grey
Bright:
black/grey
red
green
yellow
blue
magenta
cyan
white
Solarized Dark default background (ANSI bright black/grey)
Normal:
black
red
green
yellow
blue
magenta
cyan
(light)grey
Bright:
black/grey
red
green
yellow
blue
magenta
cyan
white
ANSI Black background
Normal:
black
red
green
yellow
blue
magenta
cyan
(light)grey
Bright:
black/grey
red
green
yellow
blue
magenta
cyan
white
[ Posté le 22 mai 2018 à 23:21 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/ansi_colors_and_solarized.trackback
Commentaires
Aucun commentaire
Mercredi, 7 juin 2017
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Third part of my DNS setup notes: changing the
DNSSEC
config from NSEC to NSEC3. This has be on my TODO list for over a year now,
and despite the tutorial at the ISC Knowledge
Base,
the ride was a bit bumpy.
Generating new keys
The previous keys were using the default RSASHA1 algorithm (number 5), and we
need new keys using RSASHA256 (number 8).
Generating those keys was easy. On a machine with enough available entropy in
/dev/random (such as a Raspberry Pi with its hardware random number generator)
run:
dnssec-keygen -a RSASHA256 -b 2048 -3 example.com
dnssec-keygen -a RSASHA256 -b 2048 -3 -fk example.com
Transfer the keys to the server where Bind is running, into the directory
where Bind is looking for them.
Loading the keys
The documentation says to load the keys with
rndc loadkeys example.net
but that ended with a cryptic message in the logs:
NSEC only DNSKEYs and NSEC3 chains not allowed
Apparently, the algorithm of the old keys does not allow to use NSEC3 (which I
knew) so Bind refuses to load these keys (which I didn't anticipate). I
eventually resorted to stopping Bind completely, moving away the old keys,
deleting the *.signed and *.signed.jnl files in /var/cache/bind/ and
restarting Bind. The new keys got then automatically loaded, and the zone was
re-signed using NSEC.
NSEC3 at last
I could then resume with the tutorial.
First, generate a random salt:
openssl rand -hex 4
(let's assume the result of that operation was “d8add234”).
Then tell Bind the parameters it needs to create NSEC3 records:
rndc signing -nsec3param 1 0 10 d8add234 example.com.
Then check that the zone is signed with
rndc signing -list example.com
Linking the zones
Since the keys have changed, you need to update your domain's DS record in
your parent domains DNS, using the tool provided to you by your registrar.
This step is the same as in the “Linking the zones” of the previous
part of
this tutorial.
[ Posté le 7 juin 2017 à 23:15 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/dns_3_nsec3.trackback
Commentaires
Aucun commentaire
Dimanche, 5 février 2017
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
My old NAS that I use for backups is now over 10 years old, and while it
still works and faithfully backs-up my files every night, it has an always
increasing probability to fail.
I decided to replace it with a Buffalo Linkstation 210, that offers 2 TB of
space for 140 EUR, making it cheaper than building my own device, at the risk
of not being able to use it the way I want it, being a commercial device that
wasn't designed with my needs in mind.
The way I want to use the NAS is that it boots automatically at a given
time, after which the backup script on the desktop starts, transfers the
needed files, and puts the NAS to sleep mode again. That last feature was
available on my previous device, but not anymore on the LS210. Hence the need
to make it do my bidding.
Moreover, the Web UI for administrating the LS210 is horribly slow on my
desktop due to bad Javascript code, so the less I have to use it, the better.
The device
The way to gain SSH access seems to vary depending on the exact version of the
device and the firmware. Mine is precisely a LS210D0201-EU device with
firmware version 1.63-0.04, bought in January 2017.
Initial setup
I found instructions on
the nas-central.com forum. It relies on a Java tool called
ACP_COMMANDER
that apparently uses a backdoor of the device that is used for firmware
updates and whatnots, but can apparently be used for running any kind of shell
command on the device, as root, using the device's admin user's password.
Let's assume $IP is the IP address of the device and "password" is the
password of the admin user on the device (it's the default password).
You can test that ACP_COMMANDER works with the following command that runs
uname -a on the device:
java -jar acp_commander.jar -t $IP -ip $IP -pw password -c "uname -a"
It will output some amount of information (including a weird message about
changing the IP and a wrong password ), but if you find the following in the
middle of it, it means that it worked:
>uname -a
Linux LS210D 3.3.4 #1 Thu Sep 17 22:55:58 JST 2015 armv7l GNU/Linux
Starting the SSH server is then a matter of
- enabling the SSH feature (which, on this cheap model, is disabled by
default),
- starting the SSH server,
- changing root's password to "root" so that we can login (the password can be
changed to something more secure later).
This is achieved through the following commands:
java -jar acp_commander.jar -t $IP -ip $IP -pw password -c "sed -i 's/SUPPORT_SFTP=0/SUPPORT_SFTP=1/g' /etc/nas_feature"
java -jar acp_commander.jar -t $IP -ip $IP -pw password -c "/etc/init.d/sshd.sh start"
java -jar acp_commander.jar -t $IP -ip $IP -pw password -c "(echo root;echo root)|passwd"
On some older version of the firmware, root login was disabled in SSH, and
needed to be allowed with
java -jar acp_commander.jar -t $IP -ip $IP -pw password -c "sed -i 's/#PermitRootLogin/PermitRootLogin/g' /etc/sshd_config"
but that is not the case on my device.
Once this is done, I can run
ssh root@$IP
and login with password "root" (which was set earlier).
One nasty feature of the device is that the
/etc/nas_feature file gets
rewritten on each boot through the initrd. One last step is then to edit
/etc/init.d/sshd.sh and to comment out near the beginning of the file the
few lines that check for the SSH/SFTP support and exit in case SSH is not
supported:
#if [ "${SUPPORT_SFTP}" = "0" ] ; then
# echo "Not support sftp on this model." > /dev/console
# exit 0
#fi
According to a comment
on the nas-central forum,
“The /etc/nas_feature is restored on each reboot,
so sshd does not run on boot. Even if you change the init script.”
but I
found this not to be true.
I checked that this setup really resists reboots, by logging in as root and
typing reboot. SSH access was still possible after the device had restarted.
Going further
It was then possible to setup SSH access using keys; RSA and ECDSA are
supported but not ED25519.
One missing feature is the sudo command, but I can live without it I guess.
I have then setup the device to wake up at a given time (through the “Sleep
timer” feature in the administration Web UI). It is then possible to put the
device to sleep by running as root
PowerSave.sh standby
The command is located in
/usr/local/sbin, and this path is not available
for non-interactive logins, so I wrote the following wrapper script to
shutdown the device:
#!/bin/sh
ssh root@$IP 'bash -l -c "PowerSave.sh standby"'
After having been put into standby, the device will then start automatically
on the set time, or when the “function” button on the back is pressed.
[ Posté le 5 février 2017 à 12:52 |
6
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/ssh_access_to_a_buffalo_LS210_NAS.trackback
Commentaires
Commentaire N° 1, Wolfgang
le 13 février 2024 à 14:17
Commentaire N° 2, Matthieu Weber (La Crescenta, United States)
le 13 février 2024 à 15:05
Commentaire N° 3, Wolfgang
le 13 février 2024 à 16:07
Commentaire N° 4, Wolfgang
le 13 février 2024 à 17:07
Commentaire N° 5, Albatross
le 23 février 2024 à 20:10
Commentaire N° 6, Matthieu Weber (Finlande)
le 23 février 2024 à 22:19
Mercredi, 3 août 2016
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I finally found a tutorial that explains how to patch existing Debian
packages.
I just did that for wmweather that stopped working after NOAA changed the URL
where the METAR data is published.
In a nutshell, and in case the original web page disappears, it goes like
that:
apt-get source wmweather
cd wmweather-2.4.5
dch --nmu
mkdir debian/patches # because it didn't exist
quilt new update-url.patch
quilt edit src/wmweather.c
quilt refresh
debuild -us -uc
After that I could simply install the new package that had been created.
[ Posté le 3 août 2016 à 22:10 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/patching_a_debian_package.trackback
Commentaires
Aucun commentaire
Mercredi, 27 avril 2016
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Second part of my DNS
setup
notes, this time about DNSSEC. The following notes assumes there is already a
running instance of Bind 9 on a Debian Jessie system for an imaginary domain
example.com, served by a name server named ns.example.com.
The version of Bind 9 (9.9.5) on Debian Jessie supports "inline signing" of
the zones, meaning that the setup is much easier than in the tutorials
mentioning dnssec-tools or opendnssec.
Again these notes are mostly based on the example from the ISC Knowledge
Base.
Setting up a signed zone
If you have a delegated zone (like home.example.com from the first part), do
the following for both example.com and home.example.com.
Generate the keys
On a machine with enough available entropy in
/dev/random (such as a
Raspberry Pi with its
hardware random number
generator
) run
dnssec-keygen example.com
dnssec-keygen -fk example.com
(you can add the -r /dev/urandom option to the command if you dare, if
/dev/random is too slow. It can literaly take hours to generate those keys
otherwise).
Transfer the keys to the server where Bind is running.
Configure Bind
Create a /etc/bind/keys directory where to put the keys. Ensure the
.private files belong to root, are readable by the group bind and not by
other users.
In
named.conf.options add to the
options block:
options {
…
dnssec-enable yes;
dnssec-validation auto;
dnssec-lookaside auto;
…
};
Create in /var/cache/bind a symbolic link to /etc/bind/db.example.com.
In
named.conf.local, in the
zone "example.com" block, add
zone "example.com" {
…
#file "/etc/bind/db.example.com";
file "/var/cache/bind/db.example.com";
key-directory "/etc/bind/keys";
auto-dnssec maintain;
inline-signing yes;
};
Note that the db file must point to a file in /var/cache/bind, not in
/etc/bind. This is because bind will create a db.example.com.signed file
(among other related journal files), constructed from the path of the "file"
entry in the zone declaration, and it will fail doing so if the file is in
/etc/bind, because Bind would attempt to create the .signed file in this
read-only directory.
Then reload the configuration with
rndc reconfig
Then check that the zone is signed with
rndc signing -list example.com
Linking the zones
Your registrar should provide a tool (most probably Web based) where to put DS
records for your domain.
On the DNS server, generate a
DS record with
dig @localhost dnskey example.com | /usr/sbin/dnssec-dsfromkey -f - example.com
Copy and paste these lines in the registrar's tool. After a little while, you
should be able to query the
DS record with
dig @localhost -t ds example.org
If you have a delegated zone such as
home.example.com, generate a
DS
record for that zone with
dig @localhost dnskey home.example.com | /usr/sbin/dnssec-dsfromkey -f - home.example.com
and place these lines in
db.example.com (i.e., the
db file for the
parent zone). Change the serial number of the zone in the same file and run
rndc reload
You should then be able to query the
DS record with
dig @localhost -t ds home.example.org
You can use Verisign's DNS debugging
tool to check that the signatures
are valid and DNSViz to view the chain of signatures
from the TLD DNS down to your DNS. This also helped me figure out that my zone
delegation was incorrect and caused discrepancies between my primary DNS
server and the secondary server.
[ Posté le 27 avril 2016 à 19:21 |
1
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/dns_2_dnssec.trackback
Commentaires
DNS 3: NSEC3
Commentaire N° 1, Blog & White
le 7 juin 2017 à 23:12
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Now that I have my own server, I can finally have my own DNS server and my own
domain name for my home computer that has a (single) dynamic IP address.
The following notes assumes there is already a running instance of Bind 9 on a
Debian Jessie system for an imaginary domain example.com, served by a name
server named ns.example.com and you want to dynamically update the DNS
records for home.example.com. This is largely based on the Debian
tutorial on the subject, solving the problem
that bind cannot modify files in /etc/bind.
On the server
Create a shared key that will allow to remotely update the dynamic zone:
dnssec-keygen -a HMAC-MD5 -b 128 -r /dev/urandom -n USER DDNS_UPDATE
This creates a pair of files (
.key and
.private) with names starting with
Kddns_update.+157+. Look for the value of
Key: entry in the
.private
file and put that value in a file named
/etc/bind/ddns.key with the
following content (surrounding it with double quotes):
key DDNS_UPDATE {
algorithm HMAC-MD5.SIG-ALG.REG.INT;
secret "THIS IS WHERE YOU PUT THE KEY";
};
You can then delete the two Kddns_update.+157+ files. Ensure that
/etc/bind/ddns.key belongs to "root" and to the "bind" group, and is not
readable by other users.
Then in named.conf.local, include the key file and declare a new zone:
include "/etc/bind/ddns.key";
zone "home.example.com" {
type master;
file "/var/cache/bind/db.home.example.com";
allow-update { key DDNS_UPDATE; };
journal "/var/cache/bind/db.home.example.com.jnl";
};
In /var/cache/bind create the file db.home.example.com by copying
/etc/bind/db.empty and adapting it to your needs. For convinience, create a
db.home.example.com symbolic link in /etc/bind pointing to
/var/cache/bind/db.home.example.com.
In
db.example.com (that is, the parent zone), add a
NS entry to delegate
the name
home.example.com to the DNS server of the parent zone:
home.example.com NS ns.example.com
You can now reload the bind service to apply the configuration changes.
I also found
examples of how to
test
the dynamic zone with
nsupdate.
On the home computer
I decided to use ddclient 3.8.3 because it supports dynamic dns updates
using the nsupdate tool. I backported that version of ddclient manually
from a Debian Testing package; it's written in Perl and the backporting is
trivial.
Copy
/etc/bind/ddns.key from the server to
/etc/ddns.key on the home
computer (the one running ddclient), ensuring only root can read it. Then add
the following to
/etc/ddclient.conf (be careful with the commas, there is no
comma at the end of the second last line):
protocol=nsupdate, \
zone=home.example.com, \
ttl=600, \
server=THE_IP_ADDRESS_OF_THE_DNS_SERVER, \
password=/etc/ddns.key \
home.example.com
You can then try out the new setup.
[ Posté le 27 avril 2016 à 18:15 |
1
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/dns_1_dynamic_dns.trackback
Commentaires
DNS 2: DNSSEC
Commentaire N° 1, Blog & White
le 27 avril 2016 à 19:21
Mercredi, 13 avril 2016
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
What is the minimum entropy for my home computer's password?
In recent (post-2007) Debian (and probably other) Linux distributions, the
passwords are stored in /etc/shadow using the sha512crypt algorithm.
According to Per Thorsheim,
with 2012 hardware, a single Nvidia GTX 580 could make 11,400 attempts at
brute-force cracking such a password. This means that a
log2 11,400 = 13.5 bit password could be cracked in 1 second.
To have a password that would resist a year to such a brute-force attack, one
must multiply the password complexity by 86,400×365 (seconds per year)
i.e., add 24.5 bits to the password for a total of 38 bits.
But this password is guaranteed to be cracked in a year. To make the
probability of cracking such a password much lower, let's say less than 0.01,
one must increase the password's complexity by a hundred times i.e., add
6.7 bits. We now have a minimum of 44.7 bits.
If one does not want to change the password for the next 10 years (because one
is lazy), one must again increase the complexity tenfold (that's another
3.3 bits for a total of 48 bits) and account for the increase in processing
power in the coming years. Between 2002 and 2011, CPU and GPU computing
power
has been multiplied by 10 and 100 respectively i.e., +0.37 and +0.74
bits/year. That means that the password's complexity must be increased by
0.74 ×10 = 7.4 bits. We have now reached 55.4 bits.
Now we need to guess who are the password crackers. How many such GPU will
they put together? Titan has 18,688 GPUs
(add another 14.2 bits to stay ahead of it), and the (more affordable) machine
that cracked LinkedIn leaked passwords
had 25 GPUs (requiring to add only extra 4.6 bits).
Assuming the crackers have a 25-GPU setup and not a gigantic cluster, 60 bits
should be perfectly safe. If they are a government agency with huge resources
and your data is worth spending the entirety of that cluster's energy for 10
years, 70 bits is still enough.
The same article also mentions an Intel i7, 6-core CPU would make 1,800
attempts per second i.e., 10.8 bits. For a password that must resist for 10
years, that would mean 49 bits. Titan has 300,000 CPU cores (50,000 times
more than the i7), so that makes an extra 15.6 bits for a total of 64.6 bits.
The Tianhe-2 has 3,120,000 cores,
adding 19 bits to the original 49 bits, leading to 68 bits total.
In summary, 70 bits is enough. If you are lazy and not paranoid, 60 bits are
still enough. If you think the crackers will not use more than 32 i7 CPUs
for a month to try and break your password (adding 2.4 + 21.3 bits to the
original 10.2 bits), 48.5 bits are still enough.
[ Posté le 13 avril 2016 à 19:20 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/minimum_password_entropy.trackback
Commentaires
Aucun commentaire
Samedi, 12 mars 2016
Catégories : [ Informatique ]
Le blog (et le reste de mes pages Web) a déménagé sur un nouveau serveur (une
machine virtuelle hébergée chez shellit.org. Après longue réflexion et
tergiversations, et afin de continuer la série des machines dont le nom se
termine en « kone », j'ai décidé de l'appeler « lentokone », koska se on kone
joka on pilvissä.
J'en ai profité pour recommencer à jouer les administrateurs système et j'ai
installé des serveurs DNS, SMTP, IMAP, HTTP pour gérer mon domaine moi-même.
[ Posté le 12 mars 2016 à 15:30 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/nouveau_serveur.trackback
Commentaires
Aucun commentaire
Mercredi, 9 décembre 2015
Catégories : [ Informatique ]
Au bout de 6 semaines, j'arrive à taper lentement en aveugle (ou alors vite en
faisant énormément de fautes). J'ai tendace à confondre mains droite/gauche
et majeur/annulaire. Si je me concentre ça va, mais c'est vite fatigant.
Sur le Typematrix du boulot ça va plus ou moins, mais le clavier normal
(donc tordu) de la maison est une plaie, les doigts tombent systématiquement
entre les touches du quart droit.
[ Posté le 9 décembre 2015 à 22:18 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/bepo_3.trackback
Commentaires
Aucun commentaire
Samedi, 31 octobre 2015
Catégories : [ Informatique ]
Après 8 jours, ça commence à venir, mais pas vite. Taper en aveugle demande
beaucoup de concentration.
BÉPO en disposition par défaut (tout du moins jusqu'au prochain redémarrage du
serveur X), Scroll Lock permettant de basculer vers la disposition fi :
setxkbmap "fr,fi" "bepo,classic" "grp:sclk_toggle"
[ Posté le 31 octobre 2015 à 12:12 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/bepo_2.trackback
Commentaires
Aucun commentaire
Dimanche, 25 octobre 2015
Catégories : [ Informatique ]
Vendredi (il y a 2 jours), je me suis mis au BÉPO. C'est dur et je ne tape pas
vite. Je fais des exercices.
[ Posté le 25 octobre 2015 à 11:18 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/bepo_1.trackback
Commentaires
Aucun commentaire
Vendredi, 6 mars 2015
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I just switched from using Xterm to using evilvte
but then I noticed that evilvte cannot be resize smaller. It can become
bigger, but there is no way back. Then I learned that URxvt does everything I
want (it even uses the same font as Xterm by default) with a bit of
configuration. And it's much more lightweight than evilvte (it doesn't use
GTK, that helps).
This is my
.Xresources (everything you need to know is in the man page).
*VT100*foreground: black
*VT100*background: white
URxvt.scrollBar: false
URxvt.secondaryScreen: 1
URxvt.secondaryScroll: 0
URxvt.perl-ext-common: default,matcher
! old keyword
URxvt.urlLauncher: firefox
! new keyword
URxvt.url-launcher: firefox
URxvt.matcher.button: 1
URxvt.keysym.C-Up: \033[1;5A
URxvt.keysym.C-Down: \033[1;5B
URxvt.keysym.C-Left: \033[1;5D
URxvt.keysym.C-Right: \033[1;5C
URxvt.keysym.C-Page_Up: \033[5;5
URxvt.keysym.C-Page_Down: \033[6;5
You need to merge it with X's resource database
xrdb -merge .Xresources
and then you can run the terminal.
And Firefox just restored the --remote option, so wmnetselect
should even work again (until next time, anyway). Let's say it was an
opportunity to learn about stuff…
[ Posté le 6 mars 2015 à 19:09 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/it_will_be_urxvt_after_all.trackback
Commentaires
Aucun commentaire
Jeudi, 5 mars 2015
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Since I built a customized Debian package
I could as well have my own repository. I started from this tutorial
but it's a bit out of date and has a dead link to the reprepro short-howto,
so here's a record of what I did.
First, you will need to install the reprepro package.
Then, choose a place where to put your repository (I chose my $HOME).
Origin,
Label and
Description are free-form fields.
Codename is the
same as my current Debian version, and
Architectures matches the
architectures I'm using. Then run:
mkdir -p packages/debian/conf
cd packages/debian
cat <<EOF > conf/distributions
Origin: Matthieu
Label: Mathieu's Personal Debs
Codename: wheezy
Architectures: i386 amd64 source
Components: main
Description: Matthieu's Personal Debian Repository
SignWith: yes
DebOverride: override.wheezy
DscOverride: override.wheezy
EOF
cat <<EOF > conf/options
verbose
ask-passphrase
basedir .
EOF
touch conf/override.wheezy
Now's the time to add the packages. Since
SignWith was set to
yes in the
conf/distributions file, your GPG key will be used for signing the manifest
files.
reprepro -Vb . includedeb wheezy /src/evilvte_0.5.1-1+custom_amd64.deb
reprepro -Vb . includedsc wheezy /src/evilvte_0.5.1-1+custom.dsc
Next configure your system to use the newly created repository by adding to
your
/etc/apt/sources.list (replace $HOME with the actual path to your
repository):
deb file:$HOME/packages/debian/ wheezy main
deb-src file:$HOME/packages/debian/ wheezy main
Add your GPG key to apt's keyring (replacing KEY-ID with the one of the GPG
key that was used when adding the packages earlier):
gpg -a – export KEY-ID | sudo apt-key add -
You can now run
apt-get update and it should pick the content of your local
repository. You can check that it is indeed the case:
apt-cache showpkg evilvte
Package: evilvte
Versions:
0.5.1-1+custom …
0.5.1-1 …
…
[ Posté le 5 mars 2015 à 23:19 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/local_debian_repository.trackback
Commentaires
Aucun commentaire
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Since I started with Linux, back in 1997, my xterm have been using always the
same font: a bitmap, fixed font which produces 6x13 pixels glyphs. I'm
convinced that a bitmap font is the best possible choice for not-so-high
resolution LCD monitors (I have a 17" 1280x1024 monitor which results in a
96 dpi resolution) where any vector font would inevitably produce aliased or
fuzzy glyphs. My bitmap font is crisp and has no rainbow edges (who in his
right mind could imagine that subpixel antialiasig is a good idea?).
With the xterm, I could simply specify the font as 6x13 and it would use
it. That was simple, because it was meant for it.
Today I
switched from pure X11 xterm to GTK-based evilvte
and while evilvte is apparently a great tool, it didn't want to use my beloved
6x13 bitmap font. It would use 6x12 or 7x13, but not the one in the middle.
The font is however available on the system through fontconfig, since I could
find it with
fc-match:
$ fc-match Fixed-10:style=semicondensed
6x13-ISO8859-1.pcf.gz: "Fixed" "SemiCondensed"
But evilvte, while showing "SemiCondensed" as an option in its font dialog,
just seemed to ignore it. The fontconfig documentation mentions that one can
trigger debug output by setting an environment variable
FC_DEBUG=1. With it,
I could see how Pango (GTK's font managemnt system) was interacting with
fontconfig:
fc-match Fixed-10:semicondensed
Match Pattern has 19 elts (size 32)
family: "Fixed"(s) …
style: "semicondensed"(s)
slant: 0(i)(s)
weight: 100(i)(s)
width: 100(i)(s)
…
Pattern has 18 elts (size 18)
family: "Fixed"(w)
style: "SemiCondensed"(w)
slant: 0(i)(w)
weight: 100(i)(w)
width: 87(i)(w)
…
file: "/usr/share/fonts/X11/misc/6x13-ISO8859-1.pcf.gz"(w)
That's the right font file.
While Pango:
python mygtk.py "Fixed SemiCondensed 10"
Match Pattern has 20 elts (size 32)
family: "Fixed"(s) …
slant: 0(i)(s)
weight: 80(i)(s)
width: 87(i)(s)
…
Pattern has 18 elts (size 18)
family: "Fixed"(w)
style: "Regular"(w)
slant: 0(i)(w)
weight: 80(i)(w)
width: 100(i)(w)
…
file: "/usr/share/fonts/X11/misc/7x13-ISO8859-1.pcf.gz"(w)
And that's not the right font file…
Notice the important difference: fc-match asks for a weight of 100 (and style
SemiCondensed) while Pango asks for weight 80 and width 87 (which is
apparently equivalent to semi-condensed). Since my font had a weight of 100,
it was never selected. However, when requesting a bold version (fc-match
Fixed-10:semicondensed:bold or python mygtk.py "Fixed SemiCondensed Bold
10") the same font is found (6x13B-ISO8859-1.pcf.gz, which is the bold
counterpart of my font). That took me several hours to find out.
Since the root of the problem seemd to be the weight, I needed to find out how
to make Pango tell fontconfig to use a different weight, since there is
apparently
nothing
between “Regular” (Pango 400, fontconfig 80) and “Bold” (Pango 700,
fontconfig 200). And then, completely by accident, I found
out
there is actually a middle value: “Medium” (Pango 500, fontconfig 100),
which is exactly what I neeed. But the outdated PyGTK documentation and the
well-hidden man page (and very little help from Google and DuckDuckGo in
finding a decent documentation for Pango, I must say) didn't make this any
easy.
So finally, the magic font description I put in evilvte's config is “Fixed
Medium SemiCondensed 10”. With it, Pango selects the font I want:
$ python mygtk.py "Fixed Medium SemiCondensed 10"
Match Pattern has 20 elts (size 32)
family: "Fixed"(s) …
slant: 0(i)(s)
weight: 100(i)(s)
width: 87(i)(s)
…
Pattern has 18 elts (size 18)
family: "Fixed"(w)
style: "SemiCondensed"(w)
slant: 0(i)(w)
weight: 100(i)(w)
width: 87(i)(w)
…
file: "/usr/share/fonts/X11/misc/6x13-ISO8859-1.pcf.gz"(w)
Appendix
The
mygtk.py script is a simple GTK tool I wrote for the purpose of using a
specific Pango font description and producing the fontconfig debug output.
This is the script:
import gtk
import pango
import gobject
import sys
window = gtk.Window(gtk.WINDOW_TOPLEVEL)
tv = gtk.Label("Hello World")
tv.modify_font(pango.FontDescription(sys.argv[1]))
window.add(tv)
tv.show()
window.show()
gobject.timeout_add(100, gtk.main_quit)
gtk.main()
[ Posté le 5 mars 2015 à 22:14 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/bitmap_fonts_for_my_terminal.trackback
Commentaires
Aucun commentaire
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Today I switched from using xterm (which I had been using for the past 15
years at least) to using evilvte. The reason is that evilvte allows to click
on URLs and opens a new tab in Firefox, while xterm does not. Since Firefox
removed the --remote option, wmnetselect did not anymore allow me
to open a copied URL. Since wmnetselect has no been updated since forever
and has even been removed from Debian, I thought it was time for a radical
change (yes, I changed my terminal emulator because of the Web browser. I
know).
Evilvte is one of those simplistic tools that you configure by editing the
source code (the config.h, really), so I thought that after having done
that, I may as well make my own custom Debian package. It wasn't too hard, but
since I don't plan to do this regularly, here's the process.
Get the Debianized sources:
apt-get source evilvte
Enter the directory
cd evilvte-0.5.1
Edit the config file (or whatever you want to do for your own package), save
it in the right place. In my case, the package contained a debian/config.h
customized by the package's maintainer, so I needed to modify this one rather
than the src/config.h one. During the building of the package,
src/config.h is overwritten by debian/config.h.
Then edit debian/changelog and add a new entry. By doing that, you need to
choose a new version number. I wanted to keep the original version number of
the package (0.5.1-1) but make it known that it was slightly newer than
0.5.1-1: I decided to go for 0.5.1-1+custom (after discovering that my first
choice, 0.5.1-1~custom, means that the package is slightly older than 0.5.1-1
and would therefore have been replaced during the next apt-get dist-upgrade)
by 0.5.1-1 . The description of the change is simply “Custom configuration”.
For the rest, follow the example of the existing entries in the changelog. Be
careful, there are two spaces between the author and the date.
If you have changed the upstream source code instead of only Debia-specific
files, the package building helpers will record a patch for your and let you
write some comments in the patch file, based on the new entry in the
changelog.
Then you just need to build the package:
dpkg-buildpackage
It will probably ask you for your GPG passphrase (when signing the package),
and after that, you're done. The newly created package is in the parent
directory, and ready to be installed.
cd ..
sudo dpkg -i evilvte_0.5.1-1+custom_amd64.deb
That's it!
[ Posté le 5 mars 2015 à 21:14 |
3
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/customized_debian_package.trackback
Commentaires
Bitmap Fonts for my Terminal
Commentaire N° 1, Blog & White
le 5 mars 2015 à 22:05
Local Debian Repository
Commentaire N° 2, Blog & White
le 5 mars 2015 à 23:16
It will be URxvt after all...
Commentaire N° 3, Blog & White
le 6 mars 2015 à 19:07
Jeudi, 6 février 2014
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
My new computer has a UEFI firmware. I installed Debian Wheezy, which in turn
installed the EFI variant of GRUB. For that purpose, the Debian installer made
the first partition on the hard disk drive of type VFAT and mounted in
/boot/efi.
My problem is that GRUB tends to freeze, either just before booting the kernel
(showing forever “Loading initial ramdisk”) or just after the welcome message
(“Welcome to Grub!”). Pressing the computer's reset button allowed to reboot
the computer, and everying went then fine. It seems to be possible to
reproduce the bug at will by switching off the power supply, waiting 15
seconds for the capacitors to get empty and then reboot the computer. Booting
however also hangs quite often after powering the computer off in software
(where the power supply still provides some power to the motherboard).
I read here and there that EFI GRUB was quite buggy, so I decided to switch to
PC GRUB (the variant for booting with the Legacy firmware, aka BIOS).
In a first attempt, I configured the motherboard's firmware to use “Legacy
ROM only” instead of “UEFI only”. Debian continued to boot normally with the
still installed EFI GRUB, and the freeze when rebooting after having switched
off the power supply seemed to have disappeared. It howerver froze again today
and so I decided to change from EFI GRUB to BIOS GRUB.
I first ran
apt-get install grub-pc, which complained that
/usr/sbin/grub-setup: warn: This GPT partition label has no BIOS Boot
Partition; embedding won't be possible!.
/usr/sbin/grub-setup: warn: Embedding is not possible.
GRUB can only be installed in this setup by using blocklists.
However, blocklists are UNRELIABLE and their use is discouraged..
After a bit of research on the Web,
I found someone's advice to change the flag of the FAT partition to
bios_grub. I then forced the reinstallation of grub-pc with apt-get
install --reinstall grub-pc, which didn't complain anymore.
On the next reboot however, the startup script indicated that “fsck died with
status 6”. I found out that it tried to check the VFAT partition, but since
GRUB is now installed there, it is not anymore recognized as a VFAT partition,
and fsck was legitimately skipping it. parted confirmed that fact, and
blkid does not list the VFAT partition anymore either. I therefore commented
it out in /etc/fstab and now the boot does not fail anymore.
[ Posté le 6 février 2014 à 19:23 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/changing_grub_efi_to_bios.trackback
Commentaires
Aucun commentaire
Dimanche, 15 septembre 2013
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I have a list of files in a text file, and I want to load this list into some
kind of data structure. The list is quite long, and requires to instantiate
100,000 objects in Python, all of the same type. I found out that depending on
what kind of object is used, the time it takes to instantiate all these can
vary greatly. Essentially, each line of the file is composed of tab-separated
fields, which are split into a list with Python's str.split() method. The
question therefore is: what should I do with that list?
The object must hold a few values, so basically a list or a tuple would be enough.
However, I need to perform various operations on those values, so additional
methods would be handy and justify the use of a more complex object.
The Contenders
These are the objects I compared:
A simple list, as returned by str.split(). It is not very handy, but will
serve as a reference.
A simple tuple, no more handy than the list, but it may exhibit better
performance (or not).
A class named
List that inherits from
list:
class List(list):
def a(self): return self[0]
def b(self): return self[1]
def c(self): return self[2]
A class named
Tuple that inherits from
tuple:
class Tuple(tuple):
def a(self): return self[0]
def b(self): return self[1]
def c(self): return self[2]
A class named
ListCustomInitList that inherits from
List and adds a custom
__init__() method:
class ListCustomInitList(List):
def __init__(self, *args): List.__init__(self, args)
A class named
TupleCustomInitTuple that inherits from
Tuple and adds a
custom
__init__() method:
class TupleCustomInitTuple(Tuple):
def __init__(self, *args): Tuple.__init__(self)
A class named
ListCustomInit that inherits from the
list basic type but
has the same features as
ListCustomInitList instead of inheriting them from
the custom
List:
class ListCustomInit(list):
def __init__(self, *args): list.__init__(self, args)
def a(self): return self[0]
def b(self): return self[1]
def c(self): return self[2]
A class named
TupleCustomInit that inherits from
tuple basic type but has
the same features as
TupleCustomInitTuple instead of inheriting them from
the custom
Tuple:
class TupleCustomInit(tuple):
def __init__(self, *args): tuple.__init__(self)
def a(self): return self[0]
def b(self): return self[1]
def c(self): return self[2]
A class named
NamedTuple that is made from the
namedtuple type in the
collections module:
NamedTuple = namedtuple("NamedTuple", ("a", "b", "c"))
A very basic class named
Class and that inherits from
object:
class Class(object):
def __init__(self, args):
self.a = args[0]
self.b = args[1]
self.c = args[2]
A variant of the previous that uses the
__slots__ feature:
class Slots(object):
__slots__ = ("a", "b", "c")
def __init__(self, args):
self.a = args[0]
self.b = args[1]
self.c = args[2]
A old-style class, named
OldClass, that does not inherit from
object:
class OldClass:
def __init__(self, args):
self.a = args[0]
self.b = args[1]
self.c = args[2]
The Benchmark
Each class is instantiated 100,000 times in a loop, with the same, constant
input data: ["a", "b", "c"]; the newly created object is then appended to a
list. This process it timed by calling time.clock() before and after it and
retaining the difference between the two values. The time.clock() method has
quite a poor resolution, but is immune to the process being set to sleep by
the operating systems's scheduler.
This is then repeated 10 times, and the smallest of these 10 values is
retained as the performance of the process.
The Results
The results from the benchmark are shown relatively the speed of using a
simple list. As expected, the use of a simple list is the fastest, since
it requires not additional object instantiation. Below are the results:
- 1.000 list
- 2.455 tuple
- 3.273 Tuple
- 3.455 List
- 4.636 Slots
- 5.818 NamedTuple
- 6.364 OldClass
- 6.455 Class
- 6.909 TupleCustomInit
- 7.091 TupleCustomInitTuple
- 7.545 ListCustomInit
- 7.818 ListCustomInitList
Conclusion
One can draw several conclusions from this experiment:
- Not instantiating anything is much faster, even instantiating a simple tuple
out of the original list increases the run time by 150%
- The slots feature makes object instantiation 28% faster compared to a
regular class
- Deriving a class from a basic type and adding a custom
__init__() method
that calls the parent's __init__() adds a lot of overhead (instantiation is
7 to 8 times slower)
[ Posté le 15 septembre 2013 à 15:13 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/instantiating_many_objects_in_python.trackback
Commentaires
Aucun commentaire
Jeudi, 21 mars 2013
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Passwords are difficult to generate and to remember, and once you finally know
how to type yours quicky, you don't want to change it. That's usually the time
when someone is forcing you to change it… Here is a synthesis of what I've
found out about how to generate secure passwords.
Entropy as a measure of password strengh
The strength of a password is usually expressed as its entropy, measured in
bits. In a nutshell, it expresses the total number of different passwords that
can be created (given some construction rules), represented as the base 2
logarithm of that total number. For example, if you know that a password is
composed of a single character which may be a letter (uppercase or lowercase), a
digit, a white space or a period (which conveniently makes 64 different
symbols: 26 lower case letters, plus 26 uppercase letters plus 10 digits plus
2 punctuation symbols), the entropy of that password is 6 bits (because
26 = 64). Non-integer entropy values are valid, so for example a
single lowercase letter has an entropy of approximately 4.7 (because
24.7 ≈ 26). The addition of one bit of entropy multiplies
the total number of different possible passwords by 2; a password made of 2
characters (64 symbols: upper/lowercase letters, digits and 2 punctuation
signs) has therefore an entropy of 12 bits and a password made of 8 lowercase
letters has an entropy of 37.6 bits.
The human factor
The above entropy measurement is true only if the password is truly randomly
generated, and that each symbol has an equal probability of being selected.
Humans seem to be rather bad at generating random passwords, and in Special
Publication 800-63,
the entropy of a human-generated password of length 8 is estimated to have an
entropy of 18 bits.
Moreover, if the password is a word from a natural language, the number of
possible different passwords is equal to the size of the vocabulary in that
language; for English language
this is estimated to be between 250,000 words. The entropy of a
password made of a single English word is therefore approximately 17.9 bits.
Forcing more entropy
To increase the entropy of human-generated passwords, it is quite common to
enforce rules, such as a minimum length, the use of more symbols than just
the 26 lowercase letters and forbidding the use of common words. The NIST
report above estimates that the additional symbols add 6 bits of entropy and
the dictionary check adds 5 bits. An 8 character password following all the
rules above is therefore estimated to have an entropy of 30 bits. For
comparison, a randonly-generated password of 8 character chosen amongst the
most common symbols on a computer keyword (80 symbols) has an entropy of 50.6
bits
Such password become however difficult to remember, especially if you have to
memorize several of them and are forced to change them every few months.
And they are still pretty insecure.
Cracking passwords
There are two different methods for cracking a password.
The first method consists in connecting to the service asking for the
password, and trying passwords until the right one is found. This method is
slow, one can expect to test at most a few dozen of passwords per second
(let's say 100 passwords per second). Using the entropy to measure the
strength of the attack, that represents 6.6 bits per second, or 23.0 bits/day,
or 27.9 bits/month, or 31.5 bits/year.
This gives the following times:
- 18 bits password: at most 45 minutes
- 30 bits password: at most 128 days
- 50.6 bits password: at most 560,000 years
The thing here is that reasonnably secure services will not allow that many
trials.
The second method for cracking passwords requires a list of encrypted
passwords e.g., stolen from a badly secured service. Depending on the
encryption algorithm used with those passwords and the hardware at
hand, one
can expect an attacker to try between 2,000 and 15,500,000,000 passwords per
second (between 11 and 33.8 bits/s) with a standard desktop computer (equipped
with a modern GPU).
This gives the following times:
- 18 bits password: at best 128 seconds, at worst a few microseconds
- 30 bits password: at best 6 days, at worst less than a second
- 50.6 bits password: at best 274 years, at worst 32 hours.
How many bits are needed?
The times indicated above represent the maximum time needed for cracking
the password. There is a 50% chance of cracking it in half that time, and a
10% chance of cracking it in a tenth of that time.
So if a password needs to be safe for at least 1 year, the time needed for
cracking it needs to be at least a year i.e., 33.8 + 24.9 = 58.7 bits (entropy
of the number of passwords tested per second plus the “entropy” of the number of
seconds per year). There is however a chance that the password will be cracked
in less time. Adding 1 bit of entropy will reduce the attacker's chance of
finding the password in a given time by half, and adding 10 bits reduces it to
1 chance out of 1024 to crack it in that time. 7 bits would reduce it to 1
chance out of 128, which may be sufficient as well.
How to generate such a password?
A 68.7 bits password means 15 lowercase letters, or 11
common-keyboard-symbols. These have to be selected by a true random
process, such as dice rolls, nuclear desintegration or electronic thermal
noise. 6-sided dice are easy to come by, and the
Diceware method is probably
the easiest one for generating secure and easy-to-remember passwords. A rolls of
5 dice allows to select one word in a list of 7,776, providing 12.9 bits of
entropy. The strenght of the password therefore depends on the number of words
that are selected (by repeatedly rolling 5 dice):
- 1 word: 12.9 bits, cracked in less than a microsecond
- 2 words: 25.8 bits, cracked in less than 4 milliseconds
- 3 words: 38.3 bits, cracked in less than 30 seconds
- 4 words: 51.6 bits, cracked in less than 2 days
- 5 words: 64.5 bits, cracked in less than 55 years
- 6 words: 77.4 bits, cracked in less than 423,000 years
- 7 words: 90.3 bits, cracked in less than 3231 million years
The Diceware method also allows to add a random non-letter symbol to the
password, adding about 9.5 bits of entropy for a 20 character password (about
5 words). Therefore a 5-word password with one random symbol can be considered
secure for at least a few years.
How long will the password be safe?
Between 2002 and 2011, CPU and GPU computing
power
has been multiplied by 10 and 100 respectively i.e., +0.37 and +0.74 bits/year
regarding password cracking. The rate of growth will probably not remain that
high, but if one wants to keep a password for more than a year or two, it
should be taken into consideration. For example, if a password must remain
safe for the 4 next years, add 3 bits. The 5-word password with one random
symbol will therefore be safe for the next 7 years.
One must also consider that computer clusters become affordable, and that a
25-GPU computer
has been built exactly for the purpose of cracking passwords. This type of machine
adds about 4 bits to capacity of cracking encrypted password (the “second
method” above). That makes the 5-word diceware passphrase safe for barely
over a year. Finally, cloud computing
and parasitic computing using cloud-based browsers
may reduce the safety period even further.
Conlcusion
The only truly secure passwords are long and truly random; any other
method for generating passwords will lead to easily crackable passwords, and
is therefore giving a false sense of security. Long enough passwords need to
be changed, but not too often; 3 years is a reasonnable lifetime. The Diceware
method allows to generate such password in a simple way.
Finally, memorizing a lot of passwords is difficult and induces people to
reuse the same passwords. There is a simple solution to that, promoted by
Bruce Schneier: write down your password
and keep it in your wallet.
[ Posté le 21 mars 2013 à 22:50 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/password_strength.trackback
Commentaires
Aucun commentaire
Lundi, 10 décembre 2012
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
A few months ago, I started to use ruby for work. Twice I burnt my fingers on
the following behaviour in Ruby:
def foo
"bar"
end
puts "foo = #{foo.inspect}"
if foo.nil?
foo = "quux"
puts "Not coming here"
end
puts "foo = #{foo.inspect}"
The method
foo returns the string
"bar", which is therefore not
nil. The
result any sane coder expects would be
foo = "bar"
foo = "bar"
What
actually comes out when you run this snippet is
foo = "bar"
foo = nil
I remember reading that in order to decide whether foo is a call to the
foo method or the use of the local variable foo, Ruby checks the code
before for any assignment to foo. As it happens, the local variable foo
gets assigned inside the if clause, but the statement is never executed. My
guess is that Ruby then decides that the local variable foo is put to use
after the if clause, but is never actually assigned to, and therefore its
value is nil. As it happens, the foo method still exists and returns
"bar", as expected, when called as foo().
[ Posté le 10 décembre 2012 à 22:30 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/ugly_ruby.trackback
Commentaires
Aucun commentaire
Mardi, 15 mai 2012
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique/Git ]
This is, in a nutshell, how to send commits to the (single) maintainer of a
project by e-mail.
Add the maintainer's e-mail address to the repository's config:
git config --set sendemail.to "John Smith <john.smith@example.com>"
Make a set of patches from the commits e.g.,
git format-patch HEADˆ
or
git format-patch origin/master..master
Send the patches by e-mail:
git send-email *.patch
(this sends one e-mail
per patch).
On the receiving side, the maintainer can then feed the content of each e-mail
into git am to apply the patches and record new commits.
The git send-email command is packaged separately in Debian, the package
git-email needs to be installed.
This post is based on this page
from the Chromium project.
[ Posté le 15 mai 2012 à 19:47 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/Git/email_git_patches.trackback
Commentaires
Aucun commentaire
Lundi, 14 mai 2012
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique/Git ]
Resolve a binary file conflict with Git
Found on lostechies.com
In case of conflict with a binary file during a merge, you have two choices
for resolving it:
Then commit the changes.
Show the content of a deleted file
Found on stackoverflow.com
git show commitid:path/to/file
The trick here is that one must use the full path to the file (relatively to
the repository's root)
Restore a deleted file in a Git repo
Found on stackoverflow.com
Find the last commit where the file was deleted:
git rev-list -n 1 HEAD -- thefile
Then checkout the file from the commit before that:
git checkout commitid -- thefile
[ Posté le 14 mai 2012 à 13:39 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/Git/more_git_recipes.trackback
Commentaires
Aucun commentaire
Samedi, 24 mars 2012
Traduction: [ Google | Babelfish ]
Catégories : [ Bricolage/Arduino | Informatique ]
For my car heater
controller
I decided to use Alan Burlison's
scheduler.
I like it, because it leaves the main program file reasonnably short and allows to
separate the code into multiple objects. I don't know if it makes the software
more or less easy to write/maintain, but I find it fun to do it this
way, and that's all that counts.
To implement 2-way communication between the JeeLink (master) and the JeeNode
(slave) using Jean-Claude Wippler's RF12 library, I created a Listener
object and a Speaker object that deal with receiving data and sending data
respectively, while the Protocol object implements the higher-level
protocol.
Here' how the slave's .pde file looks like. Notice how it contains only
definitions and a bit of initialization, but no big mess of code?
#define NB_ELEMENTS(a) sizeof(a) / sizeof(a[0])
Speaker speaker;
Protocol protocol(&speaker);
Listener listener(&protocol);
Task * tasks[] = { &listener, &speaker };
TaskScheduler scheduler(tasks, NB_ELEMENTS(tasks));
void setup() {
rf12_initialize(SLAVE_ID, RF12_868MHZ, HEATER_GROUP);
}
void loop() {
scheduler.run(); // infinite loop
}
Here's a sample of the
slave's Listener.
class Listener: public Task { // Task from Alan Burlison's scheduler
public:
Listener(Protocol * protocol):
protocol(protocol)
{};
bool canRun(uint32_t now); // Taks's interface
void run(uint32_t now); // Task's interface
private:
Protocol * protocol; // higher-level protocol handler
uint8_t recv_buffer[BUFFER_LEN];
uint8_t recv_buffer_len;
};
bool Listener::canRun(uint32_t now) {
if (rf12_recvDone())
return (rf12_crc == 0 && rf12_len <= BUFFER_LEN);
return false;
}
void Listener::run(uint32_t now) {
recv_buffer_len = rf12_len;
memcpy((void *)recv_buffer, (void *)rf12_data, recv_buffer_len);
if (rf12_hdr == (RF12_HDR_CTL | (MASTER_ID & RF12_HDR_MASK)))
protocol->got_ack();
else {
if (RF12_WANTS_ACK) {
rf12_sendStart(RF12_ACK_REPLY, 0, 0);
rf12_sendWait(0);
}
protocol->handle(recv_buffer, recv_buffer_len);
}
}
And there's the slave's Speaker. Note that the Spaker tries to send data only
if its buffer_len is greater than zero. This prevents calling rf12_canSend()
when it's not necessary (according to the RF12 driver, you must not call
rf12_canSend() only if you intend to send data immediately after calling it).
When the Protocol wants to send something, it needs to get the Speaker's
buffer with get_buffer(), fill the buffer with data, and then call send().
Also, I implemented a retry mechanism in case no ACK has been received from
the master.
class Speaker: public Task { // Task from Alan Burlison's scheduler
public:
Speaker();
uint8_t* get_buffer();
void send(uint8_t len, bool ack);
void got_ack(); // called by the Protocol when it gets an ACK
bool canRun(uint32_t now); // Task interface
void run(uint32_t now); // Task interface
private:
uint8_t buffer[BUFFER_LEN];
uint8_t buffer_len;
bool with_ack;
uint8_t retry_count;
unsigned long next_retry_millis;
};
bool Speaker::canRun(uint32_t now) {
if (buffer_len > 0 && retry_count > 0
&& millis() > next_retry_millis)
return rf12_canSend();
return false;
}
void Speaker::run(uint32_t now) {
if (with_ack && retry_count == 1) {
buffer_len = 0;
}
uint8_t header = (with_ack ? RF12_HDR_ACK : 0)
| RF12_HDR_DST | MASTER_ID;
rf12_sendStart(header, buffer, buffer_len);
rf12_sendWait(0);
if (with_ack) {
retry_count – ;
next_retry_millis = millis() + SEND_RETRY_TIMEOUT;
}
else
buffer_len = 0;
}
void Speaker::send(uint8_t len, bool ack) {
with_ack = ack;
buffer_len = len;
retry_count = SEND_RETRY_COUNT + 1;
next_retry_millis = millis();
}
void Speaker::got_ack() {
buffer_len = 0;
}
The master's code is very similar, you can check it
there.
[ Posté le 24 mars 2012 à 16:17 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/task_based_jeenode_communication.trackback
Commentaires
Aucun commentaire
Lundi, 13 février 2012
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique/Git ]
I thought it would be very convenient to see from the shell's prompt what
branch I am currently working on. Of course, someone had got that idea well
before me, and I found this implementation
and this variant (the second adds space
between the name of the branch and the symbols indicating the state of the
branch relative to the remote branch it is tracking).
[ Posté le 13 février 2012 à 15:30 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/Git/git_status_in_shell_prompt.trackback
Commentaires
Aucun commentaire
Vendredi, 11 novembre 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I have an asymetrical ADSL connecion (1024 kbps downstream, 512 kbps upstream)
and when I'm downloading a large file, SSH connections become unresponsive.
After a bit of reading, I found one traffic shaping script that allows to keep
responsive interactive SSH connections, at the cost of a slightly limited
download speed. The explanations are from the Linux advanced routing and
traffic control howto, in the
cookbook chapter.
The explanations goes like this:
“ISPs know that they are benchmarked solely on how fast people can download.
Besides available bandwidth, download speed is influenced heavily by packet
loss, which seriously hampers TCP/IP performance. Large queues can help
prevent packet loss, and speed up downloads. So ISPs configure large queues.
These large queues however damage interactivity. A keystroke must first travel
the upstream queue, which may be seconds (!) long and go to your remote host.
It is then displayed, which leads to a packet coming back, which must then
traverse the downstream queue, located at your ISP, before it appears on your
screen.
This HOWTO teaches you how to mangle and process the queue in many ways, but
sadly, not all queues are accessible to us. The queue over at the ISP is
completely off-limits, whereas the upstream queue probably lives inside your
cable modem or DSL device. You may or may not be able to configure it. Most
probably not.
So, what next? As we can't control either of those queues, they must be
eliminated, and moved to your Linux router. Luckily this is possible.
Limit upload speed By limiting our upload speed to slightly less than the
truly available rate, no queues are built up in our modem. The queue is now
moved to Linux.
Limit download speed This is slightly trickier as we can't really influence
how fast the internet ships us data. We can however drop packets that are
coming in too fast, which causes TCP/IP to slow down to just the rate we want.
Because we don't want to drop traffic unnecessarily, we configure a 'burst'
size we allow at higher speed.”
It really does wonders, on the condition that you set the DOWNLINK speed to
800 kbps (80% of my downlink) and the UPLINK to 440 kbps (85% of my uplink). I
tried with 900 kpbs instead of 800, and it didn't work. One day, I will take
the time to think about the why, but for now I'm just happy that it works
properly.
Next step: try to get this to work on the ADSL modem/router (luckily running
linux and accessible with ssh) instead of the desktop.
[ Posté le 11 novembre 2011 à 22:09 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/traffic_shaping.trackback
Commentaires
Aucun commentaire
Mercredi, 2 novembre 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique/Git ]
When I started to use git and read the man pages, I was sorely missing a brief
description of how Git's features and concepts relate. Now that I finally
understand (at least, I think) how Git works, I wrote this document. It's not
a tutorial (the existing ones are good enough that I don't need to write
another one), but rather a summary of how Git's main features relate to the
jargon used in the man pages.
Saving your changes
Let's say you have a set of files in your working tree. Git works by
saving a full copy (snapshot) of this set; this is called a commit. When you
want to make a new commit using Git, you first need to tell Git which files
are going to be part of this commit. You do this with the git add my_file
command. The files are then added to the index, which is the list of files
that are going to compose the commit. You then run git commit, which creates
a new commit based on the files listed in the index. You are also prompted for
a message that describes the commit. The message is structured with a heading
(the first line of the message) separated by an empty line, from the
body of the message. Lines starting with a hash symbol are comments and are
not recorded into the message.
Adding a new file to the index and creating a commit containing this file has
the side effect of letting Git track this file. If you want to create a
commit composed of all the tracked files, you can run git commit -a, which
implicitely adds all the tracked files to the index before creating a new
commit.
A commit is identified by a SHA1 hash of its content, e.g,
cdf18108b03386e1b755c1f3a3feaa30f9529390. Any non-ambiguous prefix of that
hash can be used as a commit ID e.g., cdf1810.
The add/commit mechanism allows to split a set of changes into multiple
commits (you create a commit for a subset of your files, then you create
another commit for the rest of your files).
Creating a new repository
For a new project
The command git init creates a repository in the current directory (a
.git directory that holds all the data necessary for Git to work). You can
then add the files you need to have under version control (using git add,
wildcards such as '*' are accepted) and create the initial commit with git
commit.
Copying an existing repository
To copy an existing repository, use the git clone command. Most services
that offer source code as Git repositories indicate the necessary Git command
line to run.
Finding a commit
To view a summary of the changes that have happened in the repository, you can
use git log; the top of the list is the most recent commit. To view the
succession of changes (as diffs) that were made, use git log -p.
Git does its best not to lose anything you have recorded. The command git
reflog shows a log of how the tip of branches have been updated, even if you
have done acrobatic things.
Branches
When you make changes to your working tree and create a new commit, Git
links the new commit to the commit that represents the state of the working
directory before the changes (called in this context the parent of the new
commit). The chain composed of the new commit, its parent, its parent's parent
and so on, is called a branch. The name of the default branch is “master”.
The most recent commit in a branch is called its HEAD.
A branch is nothing more than a name and the commit identifier of its tip;
this is called a ref. For example refs/heads/master is the ref for the
master branch. Finding the commits that compose the branch is a simple matter
of following the tip's parent, and the parent's parent, and so on.
If you can decide to fork your work at some point, create a new branch
by running git branch new_branch. This command creates the branch, but does
not switch to that branch (changes and commits will still be appended to the
current branch). To effectively change branch, you need to checkout the
HEAD of the new branch by running git checkout new_branch. From this point
on, changes and commits will be appended to the new branch.
Merging
If at some point it is necessary to merge the content of e.g., the new
branch into the “master” branch, you need to checkout “master” and then
run git merge new_branch.
If Git doesn't know how to merge two branches, it complains about conflicts
and lets the user edit the incriminated files by hand. This is done by
choosing, in sections of these files indicated with <<<<<<
and >>>>>>> markers, which variant is to be retained.
Once the editing has been made, the changes need to be committed (with git
commit -a).
Checking out
You can checkout any commit with git checkout and thus have your
working directory reflect the state of the repository at any point in time.
When you do that, you are not on any branch anymore, which will cause various
warning messages (such as “You are in 'detached HEAD' state”) and cause Git
to behave in a way you may not expect (that is, if you don't understand
properly yet how Git works). To go back to a “normal” situation, just run
git branch master (or any other branch that exists). To prevent going into
detached HEAD state, use git checkout -b new_branch to create a new
branch that starts at <commit>.
If you have made local changes, Git won't let you checkout another branch. You
must either commit them or reset the working tree before being allowed to do
the checkout.
Reset
The command git reset allows to do multiple things. One of its most common
use (git reset --hard) is to cancel all changes you have made to
the working tree since the last commit.
If you specify a commit ID after git reset, it will move the HEAD of the
current branch back to that commit, which becomes the new HEAD; all commits
after this point are removed from the branch (but not from the repository! You
can always restore the old HEAD by finding its commit ID with git reflog).
Working with remote repositories
Pull (and Fetch)
Some time after you have cloned a public repository, you may want to update
your local copy so that it mathtches the latest version available at the
original repository. This update is done with with git pull. When the
repository was cloned, Git had created a remote (a link to the source
repository) called by default “origin”. Below the hood, git pull calls
git fetch to retrieve the commits from all the relevant branches on
“origin”, and then calls git merge to merge those changes with the local
current branch.
Note that refs/remotes/origin/master is the ref to the master branch at
“origin”, but it is actually a branch stored locally that reflects the
“master” branch on the “origin” repository. This kind of ref is used for
specifying what remote branch is tracked by what local branch when using
git fetch. Typically, +refs/heads/:refs/remotes/origin/ indicates that
e.g., the local branch “master” tracks the remote branch “origin/master”
(“*” represents a wildcard).
Push
If you have writing permissions on the remote repository, you can send your
changes using git push (it defaults to the “origin” remote). Note that the
HEAD of the branch to which you push changes must be the parent of your
changes. If this is not the case, the push will fail and you will be asked to
first pull from the remote repository to get the latest version, fix potential
conflicts and only then push your changes.
It is also important to remember that you cannot normally push to a repository
that has a working tree. The remote repository must have been created with the
git init --bare command.
[ Posté le 2 novembre 2011 à 08:36 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/Git/git_in_a_very_small_nutshell.trackback
Commentaires
Aucun commentaire
Dimanche, 23 octobre 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique/Git ]
Here are a few recipes I use with git.
Using git log
Show which files have been modified by the commits: git log
--name-status
View the successive changes for a given file: git log -p -- my_file
(latest change first)
View the changes at word-level instead of line-level: git log
--color-words
Make --color-words more readable with LaTeX files: add *.tex diff=tex
to the repository's .git/info/attributes or to your $HOME/.gitattributes
(read man gitattributes for more info on this, it supports other languages
too)
Browseable Web Repository
To make an online, browsable web repository on a web server (I assume you have
ssh access to it).
On the server, run:
$ mkdir some_directory
$ cd some_directory
$ git init
$ git config receive.denyCurrentBranch ignore
$ cat > .git/hooks/post-receive <<EOF
#!/bin/sh
GIT_WORK_TREE=.. git checkout -f
GIT_WORK_TREE=.. git update-server-info --force
EOF
$ chmod a+x .git/hooks/post-receive
The in the source repository, run:
$ git remote add web username@my.web.server:path/to/some_directory/.git
$ git push web master
(“username”, “my.web.server” and “path/to/” are exactly what you think
they are.) Note the “.git” at the end of the path, it has to be there
because git push is going to send its data into that directory.
When you run git push web master to upload the content of the source
repository to the web repository, the post-receive hook checks out the
latest version. The next time, you don't need to specify the “master” branch
any more, simply running git push web is enough.
[ Posté le 23 octobre 2011 à 15:57 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/Git/git_recipes.trackback
Commentaires
Aucun commentaire
Mercredi, 12 octobre 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Autofs allows to automatically mount a filesystem when changing directory to
the mounting point. The process is frozen while the file system is being
mounted, and then the chdir() completes and enters the root of newly mounted
filesystem.
I have been using autofs for several years, at first for mounting USB sticks,
but now also for SMB shares and SSHFS. It is meant to be used for command-line
users, I don't doubt that modern desktop environments provide the same features
for GUI users.
The following describes my setup on a Debian Squeeze; there may be a more modern
way of doing things (the original setup was on a Debian Sarge). I assume that
you know how to administrate a Debian system (in other words, I won't be held
responsible for damaging your system if you follow those instructions without
understanding what they mean).
Autofs
The first step is to install the autofs, bsdutils, coreutils,
lockfile-progs, gawk (or mawk), sed and the util-linux packages
(most of those are probably installed already). The wget package (and
command) allows me to write concise commands below, but feel free to use
any other tool to download the necessary files from my web page.
USB Automounter
This setup allows to mount automatically any USB Mass Storage device, without
the need to manually configure anything (as is the case in this Debian
tutorial).
Edit as root the /etc/auto.master and add the following line:
/media /etc/auto.usb --timeout=3
Then run the following as root:
# mkdir -p /media
# mkdir -p /var/run/usbautomount
# mkdir -p /etc/usbautomount
# wget -O /etc/usbautomount/usbautomount http://weber.fi.eu.org/software/autofs/usbautomount
# chmod 755 /etc/usbautomount/usbautomount
# wget -O /etc/udev/usbautomount.rules http://weber.fi.eu.org/software/autofs/usbautomount.rules
# cd /etc/udev/rules.d
# ln -s ../usbautomount.rules z60_usbautomount.rules
# /etc/init.d/autofs restart
You then need to edit /etc/usbautomount/usbautomount to change references to
mweber to your own username, and possibly change the mounting options (see
line 142 of the script). I still use latin1 as a character encoding, so I want
filenames to be automatically translated into latin1 for VFAT filesystems.
Other filesystems are mounted without particular options.
The idea here is that when you plug a USB Mass Storage device into the
computer, udev runs the usbautomount script that creates a name based on
the USB device's vendor, model, instance (in the case the physical device
contains more than one USB Mass Storage device, such as multi-card readers or
smartphones with internal and removable flash memory) and partition number,
creates a symlink in /var/run/usbautomount that points to a directory of the
same name in /media. When you access the symlink, automount creates the
directory in /media and mounts the file system from the USB device to that
directory.
If you chdir() out of that directory, after 3 seconds automount unmounts
the filesystem. If you chdir() into the directory again, automount mounts
it again. The short timeout for automatic unmounting allows to unplug the
device almost immediately after cd-ing out of the mount point (provided that
there is no data to be written onto the device anymore). When you unplug the
device, a script (generated by usbautomount when the device was plugged in)
is run to remove the symlink from /var/run/usbautomount.
The cherry on the cake of this setup is the following:
$ mkdir $HOME/mnt
$ ln -s /var/run/usbautomount $HOME/mnt/USB
This way, $HOME/mnt/USB is automatically populated with links to the devices
that you plug to your computer.
SMB/CIFS shares
The smbclient and cifs-utils packages need to be installed.
Run as root:
# mkdir -p /mnt/smb
Edit as root the /etc/auto.master and add the following line:
/mnt/smb /etc/auto.smb --timeout=10
(/etc/auto.smb comes with the autofs package).
Run this as your regular user:
$ ln -s /mnt/smb $HOME/mnt/smb
If you have an SMB/CIFS server named "foo" containing shares called "bar" and
"quux", then going into /mnt/smb/foo will mount "bar" and "quux" in
/mnt/smb/foo/bar and /mnt/smb/foo/quux. Automatic unmounting will happen
10 seconds after leaving /mnt/smb/foo.
If "foo" requires credentials (login and password), you can put them in
/etc/auto.smb.foo as follows:
username = my_username
password = my_password
SSHFS
SSHFS itself requires some amount of setup. I will assume in the following
that the client computer is called "local" and it accesses using SSH and
SSHFS a remote computer called "remote" with user "user".
First, install the sshfs package. Then you need to create an SSH key for
root@client, and authorize this key for user@remote. In the end, root@local
must be able to log into user@remote using an SSH key instead of a password.
Once this is working, run as root:
# mkdir -p /mnt/ssh
Then edit /etc/auto.master as root and add the line:
/mnt/ssh /etc/auto.ssh --timeout=10,--ghost
Then create /etc/auto.ssh and add a line that looks like this (change the
"user", and "remote" as needed):
remote -fstype=fuse,rw,nodev,nonempty,noatime,allow_other,max_read=65536 :sshfs\#user@remote\:
By default, SSHFS will mount the home directory of "user@remote" into
/mnt/ssh/remote. If you need to acces another directory (e.g., /tmp),
just append this path to the end of the line in /etc/auto.ssh:
remote-tmp -fstype=fuse,rw,nodev,nonempty,noatime,allow_other,max_read=65536 :sshfs\#user@remote\:/tmp
Finally, run this as your regular user:
$ ln -s /mnt/ssh $HOME/mnt/ssh
CDROM
It just came to my mind the other day that I could automount CD and DVD as
well, but I haven't thought about the details yet. I remember the feature to
be very annoying in Solaris twelve years ago, where the system was mounting
the CD in a directory named after the label of the CD's filesystem, and never
removing this directory. After mounting a few discs, the automount directory
was filled with various directories with abtruse names, and you had to guess
which one contained your data (I suppose mount would have told me what I
wanted to know, I don't remeber if I tried that).
[ Posté le 12 octobre 2011 à 11:49 |
3
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/autofs.trackback
Commentaires
u(n)mount ?
Commentaire N° 1, tth (Toulouse, France)
le 8 septembre 2011 à 07:05
Commentaire N° 2, Matthieu Weber (Jyväskylä, Finlande)
le 8 septembre 2011 à 07:36
Autofs and CD drive
Commentaire N° 3, Blog & White
le 8 septembre 2011 à 09:06
Dimanche, 18 septembre 2011
Catégories : [ Informatique ]
La fonte Stork Bill ne possède pas
de caractère accentué du tout. Pour fignoler le livret de règles du Decktet,
il me fallait un “ä” et un “ö” pour écrire “Quäsenbö” (le titre d'un
jeu). J'ai donc bricolé un tréma à la main à partir de deux points:
\makeatletter
\newcommand{\umlaut}[1]{%
\sbox\@tempboxa{#1}%
\@tempdima -.5\wd\@tempboxa
\@tempdimb 1.1\ht\@tempboxa
\sbox\@tempboxa{..}%
\advance\@tempdima -.5\wd\@tempboxa
#1\hskip\@tempdima\raisebox{\@tempdimb}{\usebox\@tempboxa}%
}
La commande s'utilise de cette manière:
Qu\umlaut{a}senb\umlaut{o}
Le résultat est potable pour la fonte en question, qui en tant que fonte
décorative n'a pas besoin d'être parfaitement régulière, mais ne donne rien de
bon avec par exemple lmodern (qui n'en a pas besoin de toutes façons
puisque cette dernière contient déjà les caractères accentués idoines).
[ Posté le 18 septembre 2011 à 15:52 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/trema_manuel_en_latex.trackback
Commentaires
Aucun commentaire
Jeudi, 8 septembre 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
After yesterday's tutorial on Autofs, I gave
some thought on using Autofs to automatically mount a CD/DVD. Here's the
result (read the previous tutorial first for complete information).
Run as root:
# mkdir -p /mnt/cdrom
Then edit /etc/auto.master as root and add the line:
/mnt/cdrom /etc/auto.cdrom --timeout=10
Then create /etc/auto.cdrom and add a line that looks like this (change
/dev/cdrom to the proper device if needed):
cd1 -fstype=iso9660,ro,nosuid,nodev :/dev/cdrom
(shamelessly copied from the supplied /etc/auto.misc).
Finally, run this as your regular user:
$ ln -s /mnt/cdrom/cd1 $HOME/mnt/cdrom
This setup is a bit crooked, because autofs is designed to watch one
directory (/mnt/cdrom in this case) and create different subdirectories for
different devices. In this case howerver we have only one device, that we mount
always to the same point. On the brighter side, if you have more than one
CD/DVD/floppy/zip drive, you can rename references to cdrom as removable,
and add multiple lines to /etc/auto.removable, one for each drive. See
/etc/auto.misc (that file comes by default with the autofs package) for
extra possibilities of configuration.
[ Posté le 8 septembre 2011 à 15:59 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/autofs_and_cd_drive.trackback
Commentaires
Aucun commentaire
Mardi, 23 août 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]

It took about a week to generate a bit over 100 MB of random data with the
arduino-based hardware random number generator.
I used the JeeLink-based one, and the last chunk of random data (50 MB) was
generated at a speed of 1562 bits/s.
And now for some statistical tests.
Fourmilab's ent test returns:
Entropy = 7.999998 bits per byte.
Optimum compression would reduce the size
of this 106315776 byte file by 0 percent.
Chi square distribution for 106315776 samples is 240.83, and randomly
would exceed this value 72.90 percent of the times.
Arithmetic mean value of data bytes is 127.4987 (127.5 = random).
Monte Carlo value for Pi is 3.140987091 (error 0.02 percent).
Serial correlation coefficient is 0.000165 (totally uncorrelated = 0.0).
I also ran the Dieharder
test suite, which ran 40 tests on the data. Out of those, I got:
- 34 PASSED
- 1 POOR (1 RGB Bit Distribution Test out of 12 instances of the test)
- 2 POSSIBLY WEAK (Diehard OPSO and Diehard Squeeze Test)
- 3 FAILED (Diehard Sums Test and two instances of Marsaglia and Tsang GCD
Test)
At the end of the series of tests, the software indicates that “The file
file_input_raw was rewound 181 times”, meaning that I should get a lot more
random data than 100 MB (ideally 18 GB, which means running the generator for
3.5 years) not to have the rewind the file for any of the tests.
The important question is however: 34 passed out of 40, is it good enough or
not?
[ Posté le 23 août 2011 à 10:48 |
2
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/dieharder_test.trackback
Commentaires
where are the datas ?
Commentaire N° 1, tth (Montpellier, France)
le 23 août 2011 à 10:00
Commentaire N° 2, Matthieu Weber (Jyväskylä, Finlande)
le 23 août 2011 à 10:47
Jeudi, 18 août 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
Angela Bartoli
To protect the password card
from theft, there is one possibility. First, randomly generate and memorize a
secret key composed of 12 numbers between 0 and 35 (one for each line of the
card). Then for each letter of the mnemonic, shift this letter to the right
(looping around the end of the line back to its beginning if needed) by the
amount indicated by this line's secret key's digit before reading the symbol.
For an 8-symbol mnemonic, the entropy of this secret key is 41.4 bits, which
gives a reasonnable amount of protection to the card even if it is stolen.
One obvious drawback is of course the strain it puts on the brain (although
some may say it's good for the organ's health to work it out this way) and the
time it takes to read one password. Another drawback is that the secret key is
hard to remember, and if you forget it, you loose all your passwords.
Translating the secret key into letters and digits might make it easier to
remember.
[ Posté le 18 août 2011 à 17:24 |
pas de
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/a_more_complicated_passwordcard.trackback
Commentaires
Aucun commentaire
Mardi, 16 août 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]

The PasswordCard
sounds like a good idea (and it actually may be in practice), but I don't like
it so much for three reasons:
- The entropy is too low (64 bits spread over 232 symbols) and generated from
an unknown source of entropy.
- You have to memorize a cryptic symbol and a color for each password, which
makes it easy to forget which symbol/color pair is associated with what
password.
- I didn't invent it :)
My current idea is to generate a similar card using a hardware random
number generator
so that each symbol on the card has an entropy of 6 bits (2592 bits in total
on he card). I also would like to get rid of the method that consists in
choosng one spot on the card and reading in one direction, and instead use the
card as a lookup table for a substitution cipher: you choose a cleartext
mnemonic for a given website with a length corresponding to the length of the
password you want to generate (e.g., “EXAMPLEC” for an 8-symbol password to
be used on example.com), and you generate the corresponding password by
looking up the symbol corresponding to “E” on the first row of the card,
then the one corresponding to “X” on the second row, “A” on the third,
“M” on the fourth, and so on.
The drawbacks are numerous:
- Reading a password this way is very slow and error-prone (the
alternating gray and white areas and the repeated header lines make it only
slightly less painful).
- Generating two passwords from the same card is fine as long as the two
mnemonics don't share the same characters in the same positions (e.g.,
“EXAMPLEC” and “EXNIHILO” share “EX” in positions 1 and 2) (if this is
the case, the entropy of those particular symbols will be divided by the
number of passwords sharing them).
- The mnemonics are meant to be easy to remember, and therefore easy to guess
by the thief of the card (that's howerver only slightly worse than the case of
the stolen PasswordCard).
- It requires a computer to generate a card that is readable in a small
format, so the random bits are temporarily stored on a system that may be
compromised (if the physical size of the card does not matter, you can
generate such a card by rolling a pair of 6-sided dice about 729 times and
writing the symbols down by hand).
There is one benefit though: the card looks very geeky :)
As usual, any comment/idea/criticism is welcome.
[ Posté le 16 août 2011 à 23:14 |
1
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/a_better_passwordcard.trackback
Commentaires
A More Complicated PasswordCard!
Commentaire N° 1, Blog & White
le 17 août 2011 à 18:19
Lundi, 15 août 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Bricolage/Arduino | Informatique ]
Software random number generators are usually so-called pseudo-random number
generators, because they produce a deterministic sequence of numbers that have
some of the properties of true random numbers. Obtaining genuinly random
numbers howerver requires a non-deterministic processus as the source of
randomness. Thermal noise in electronics or radioactive decay have been used,
usually requiring an external device to be built and plugged to the computer.
Peter Knight's TrueRandom
generates random bits by using the Arduino's ADC (with nothing connected to
the analog input pin) to measure electronic noise. It flips the pin's
internal pull-up resistor while the measure takes place to increase the amount
of noise. The software then keeps only the least significant bit of the
result, filters it using Von Neumann's whitening algorithm (read pairs of bits
until they are of different values and return 0 (respectively 1) on a 01
(respectively 10) transition). There are several functions that generate
different types of numbers based on those random bits.
I reused that code, modified it to allow using another pin than the Arduino's
Analog0 and I made my own random number generator. I also wrote a Python script
that reads the bits from the serial port, uses the SHA-1 hashing algorithm to
distil the data (the raw data has about 6 bit of entropy per byte, distillation
produces data with 7.999 bits of entropy per byte; based on the work of Jeff
Connelly on IMOTP) and writes them to the
standard output or into a file. On my Duemilanove, it can output about 1500
bits/s, while it outputs 1300 bits/s on a JeeLink.
The latter makes it an easy-to-transport device that is reasonnably sturdy and
fits in the pocket, even if its features (it contains a radio transceiver) are
a bit overkill for the job (not to mention expensive).
I also adapted the core of the TrueRandom software to run on my
ButtonBox (which
is conveniently always connected to my desktop computer). There the
output rate is a mere 300 bps, but it's still reasonnably fast for generating
a few random numbers when needed (for example for generating one's own
PasswordCard).
The access to the ButtonBox is shared among multiple clients using
button_box_server.py,
so a modified Python script was used for obtaining the stream of random bits
through the button_box_server.
I haven't had the patience to generate a few megabytes of random data to test
the generator with the DieHarder
test suite, but the output of Fourmilab's ent
test tool looks reasonnable.
[ Posté le 15 août 2011 à 11:08 |
2
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Bricolage/Arduino/hardware_random_number_generator.trackback
Commentaires
A Better PasswordCard?
Commentaire N° 1, Blog & White
le 16 août 2011 à 23:05
Dieharder Test
Commentaire N° 2, Blog & White
le 23 août 2011 à 09:48
Vendredi, 12 août 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
It all started a few days ago with this Xkcd strip.
Someone pointed it out passwordcard.com to me,
and it made me wonder how safe are the passwords generated with that tool.
Those passwords are meant to be used on all those websites that require you
to create a user account with a password. Using a single password for all those
web sites means that when the attacker of one of those websites gets your
password, he can access your account on every other website where you have an
account.
Beware that I'm no mathematician, and neither am I a specialist in
cryptography or information theory, but here are my thoughts on this system.
The generator is based on what looks like a 64-bit key, so in theory, the
entropy is 64 bits, which is reasonnably much (it would take 6x108
years to break at 1000 attempts per second). However, since you need to feed
the key to an unknown web server, the practical entropy is much less, since
someone else than you knows the key. But let's assume you can generate the
card yourself on a secure computer.
The symbols on the card are upper- and lower-case letters, and digits, which
makes overall 62 possible combinations. This gives 5.95 bits of entropy per
such symbol, if the symbol is randomly generated. Since the card is generated
from 64 bits of entropy, you can take up to 10.7 symbols to generate one or
more passwords without loosing any entropy. That is, a password made of one
symbol will have 5.95 bits of entropy, a password made of two symbols will
have twice that (11.9 bits), three symbols will be 17.9 bits and so on. If you
take more than 10.7 symbols, the entropy of each symbol will be reduced, so
that the entropy of the symbols in all your passwords altogether will never
exceed 64 bits. For example, if you take 16 symbols to make 2 passwords of 8
symbols each, the entropy of each password will be 32 bits instead of the 47.6
bits of a single, 8-symbol password. A 32-bits-of-entropy password takes 50
days to break (at the example rate above) against about 7000 years for the
47.7-bit-of-entropy password.
Here are a few examples of password types and strengths:
- 1 password of 6 symbols: 35.7 bits of entropy, cracked in 1.8 years
- 1 password of 7 symbols: 41.7 bits of entropy, cracked in 112 years
- 1 password of 8 symbols: 47.7 bits of entropy, cracked in 7000 years
- 2 passwords of 6 symbols each: 32 bits of entropy, cracked in 50 days
- 2 passwords of 7 symbols each: 32 bits of entropy, cracked in 50 days
However, if the card is stolen, the thief only has to test a few tens of
thousands combinations to find a password made of 4-8 symbols (29 x 8 symbols,
8 reading directions and 5 possible password-lengths is 55680), which
represent 15.8 bits of entropy and takes less than a minute to crack.
Loosing the card is therefore a bad move.
As a conclusion, the password card is fine on the following three conditions:
- Use a real random number for the key (e.g., by rolling 25 times a 6-sided
die) or a hardware random number generator (there will be a post on that
soon).
- Use the card for passwords totalizing no more than 10 symbols (best to use
only one password of 8, 9 or 10 symbols).
- Do not lose your PasswordCard.
Disclaimer: once again, I'm no specialist in cryptography or information
theory, but the above is based on how I understand those things. It may be
completely wrong.
[ Posté le 12 août 2011 à 21:52 |
2
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/password_management_with_passwordcard.trackback
Commentaires
Hardware Random Number Generator
Commentaire N° 1, Blog & White
le 13 août 2011 à 16:32
A Better PasswordCard?
Commentaire N° 2, Blog & White
le 16 août 2011 à 23:05
Samedi, 9 juillet 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I followed my
dream,
and I wrote the Automatic Transparent Syntax HIghlighting software.
I have files (mainly source code) put as-is on my web site. Those files can be
browsed with a regular web browser, and Apache's internal file indexing is
used for accessing the directory structure. When the user requests a (source
code) file of a known type, it would be nice to highlight the syntax.
atshi.php does just that, automatically (no need for the webmaster to
manipulate the files) and transparently (the user doesn't know a PHP program
is being executed).
You can view the code, highlighted
by itself of course (recursive computing is fun). It expects to be called as
/path/to/atshi.php/path/to/example.pl and uses the PATH_INFO variable to
find the path to the file to be displayed (in the example above,
example.pl). It uses the GeSHi library for
the actual syntax coloring (which is therefore a dependency), and
theoretically supports any file format/programming language supported by
GeSHi. In practice however, ATSHi detects the files that it should highlight
(source code must be highlighted, but .tar.gz or .jpg must not) by checking
first the filename's extension, or, if the file doesn't have one, checking the
“magic header” (the one starting with #!) followed by the name of the
interpreter. It also recognizes the filename Makefile. If it's unable to
recognize the file, it simply sends its content (with proper Content-Type
header) to the browser and lets the latter deal with it. Finally, the
highlighted version also provides a link at the top of the page for
downloading the raw file (atshi.php sends the raw file instead of the
highlighted version when you append “?src” to the URL).
But this was all quite a simple job, and even if it was my first
PHP program, it was quite simple (PHP is an horrible language, but the doc is
good, which helped a lot). The real problem was getting Apache doing my
bidding. Here's a sample of the .htaccess I use:
RewriteEngine on
RewriteRule ˆlatex/latex.css - [L]
RewriteRule ˆpoppikone/poppikone.css - [L]
RewriteCond /home/mweber/weber.fi.eu.org/www/$1 -f
RewriteRule ˆ((software|leffakone|poppikone|latex)/.*)$ /atshi/atshi.php/$1
The two top RewriteRule (with the L flag) prevent ATSHi from highlighting the
stylesheets used in the corresponding directories (those stylesheets must be
sent as-is to the browser). The bottom RewriteRule actually catches specific
paths and rewrite the URL using atshi.php. Finally, the RewriteCond just
above allows rewriting only if the path (identified as $1 when the regexp in
the RewriteRule below is evaluated) is a regular file (highlighting
directories doesn't make sense, does it?); note that you must put an absolute
path in the condition.
The difficult part here was not really to get the URL rewriting properly
written (although mentioning the absolute path trick in Apache's doc would
have been nice). The really difficult part was to find out that the bloody
Firefox always looks in its cache instead of asking the server if something
has changed. So after making a change, Firefox still didn't show what was
supposed to be showing… Erasing the cache before every test is therefore a
must.
[ Posté le 9 juillet 2011 à 20:01 |
2
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/atshi.trackback
Commentaires
Nice !
Commentaire N° 1, tth (Toulouse, France)
le 10 juillet 2011 à 20:10
Commentaire N° 2, Matthieu Weber (Avranches, France)
le 12 juillet 2011 à 11:13
Mercredi, 6 juillet 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
I had a dream last night, where I added automatic syntax coloring to the
source code files that can be found on my website. These are currenty simply
put in directories and accessible through the web server, and colors would
make them more readable (I'm not sure anyone is reading those, but who cares).
The idea would be to use Apache's URL rewrite engine to serve a
CGI/PHP/something page that reads the source code and spits out an HTML
version with colors and whatnot.
I just found GeSHi, a tool written in PHP that
does exactly that. It shouldn't be too difficult to implement.
[ Posté le 6 juillet 2011 à 13:18 |
1
commentaire |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/syntax_coloring.trackback
Commentaires
ATSHi
Commentaire N° 1, Blog & White
le 9 juillet 2011 à 12:27
Samedi, 5 mars 2011
Traduction: [ Google | Babelfish ]
Catégories : [ Informatique ]
« Alors tu vois, le processeur c'est comme le moteur de ta voiture. Et le
clavier c'est comme le volant… – Et le système d'exploitation c'est comme
l'essence alors ? – Euh… »
C'est n'importe quoi hein ? La comparaison avec la voiture ne vaut pas
tripette, parce que la voiture n'est pas un automate programmable (enfin, pas
encore). Voila une comparaison qui me paraît plus correcte (arrêtez-moi si je
me trompe): le restaurant. Dans un restaurant et dans le désordre, on
trouve:
- Le cuisinier : c'est lui qui fait (presque) tout le travail, comme le
processeur.
- Le cuisinier lit des recettes et les exécute : ce sont les programmes.
- Les recettes sont composées de gestes à effectuer qui indiquent au
cuisinier comme agir: ce sont les instructions.
- Les recettes indiquent comment transformer des ingrédients crus (viande,
légumes…) : ce sont les données fournies en entrée au programme.
- Ces ingrédients sont transformés en plats : ce sont les données fournies
en sortie par le programme.
- Les ingrédients et les plats doivent être posés quelque part à un moment
donné, par exemple sur des plans de travail : ces derniers servent de
mémoire centrale.
- Certains ingrédients crus doivent être stockés pendant un certain temps,
par exemple dans des réfrigérateurs : ce sont les mémoires de masse.
- Il existe un certain nombre d'opérations qui sont souvent répétées et que le
cuisinier a appris à effectuer lors de sa formation professionnelle (émincer,
fouetter, incorporer, ciseler…): ces instructions sont l'équivalent du
noyau du système d'exploitation.
- Il existe aussi des recettes de base qui sont souvent
répétées et qui entrent dans la composition des plats (roux, bouillon, pain…) :
elles forment l'interface de programmation qui sert de base à tous les
programmes. Certaines de ces recettes peuvent être commandées directement par le
client (le pain par exemple), et représentent les logiciels utilitaire (ou
commandes de base) fournies avec le système d'exploiatation.
- Le restaurant a des clients : ce sont les utilisateurs.
- Les client s'addressent à un serveur : ce dernier joue le rôle de
l'interface utilisateur.
- Le client peut choisir dans un menu ce qu'il désire manger, et donc les
recettes que le cuisinier va executer : ce menu est la liste des programmes
que l'utilisateur peut lancer, qui sont parfois regroupées dans un menu
(déroulant ou non).
- dans les restaurants, le cuisinier est rarement seul, il est aidé par le
boulanger, le patissier, le saucier: ce sont des coprocesseurs,
spécialisés dans l'exécution de certaines tâches.
Enfin, on peut considérer que les casseroles sont comme les registres du
processeur, elles servent de stockage temporaire pour les opérations
élémentaires.
Après, la comparaison a ses limites: on peut copier des données, mais on ne
copie pas un gateau au chocolat…
Aussi, il manque la possibilité au client de donner des ingrédients à la
cuisine, c'est à dire à l'utilisateur d'entrer des données dans l'ordinateur.
[ Posté le 5 mars 2011 à 22:00 |
2
commentaires |
lien permanent ]
Adresse de trackback
https://weber.fi.eu.org/blog/Informatique/comparaison_ordinateur.trackback
Commentaires
co-proc ?
Commentaire N° 1, tth (Toulouse, France)
le 5 mars 2011 à 12:04
Commentaire N° 2, Matthieu Weber (Jyväskylä, Finlande)
le 5 mars 2011 à 12:45
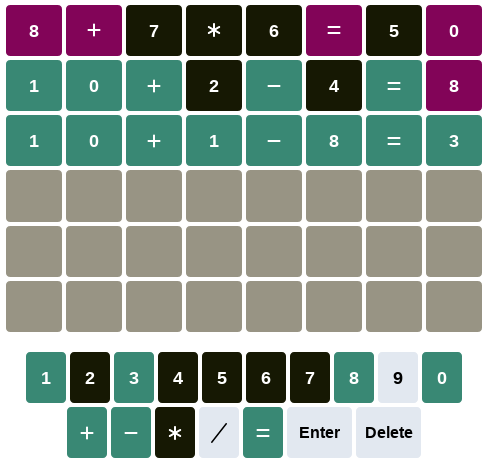








Sadly, these instructions don't work as of Dec 2021. The OpenARC package is invalid for downloading, let alone installation.