Task-Based JeeNode Communication
Traduction: [ Google | Babelfish ]
Catégories : [ Bricolage/Arduino | Informatique ]
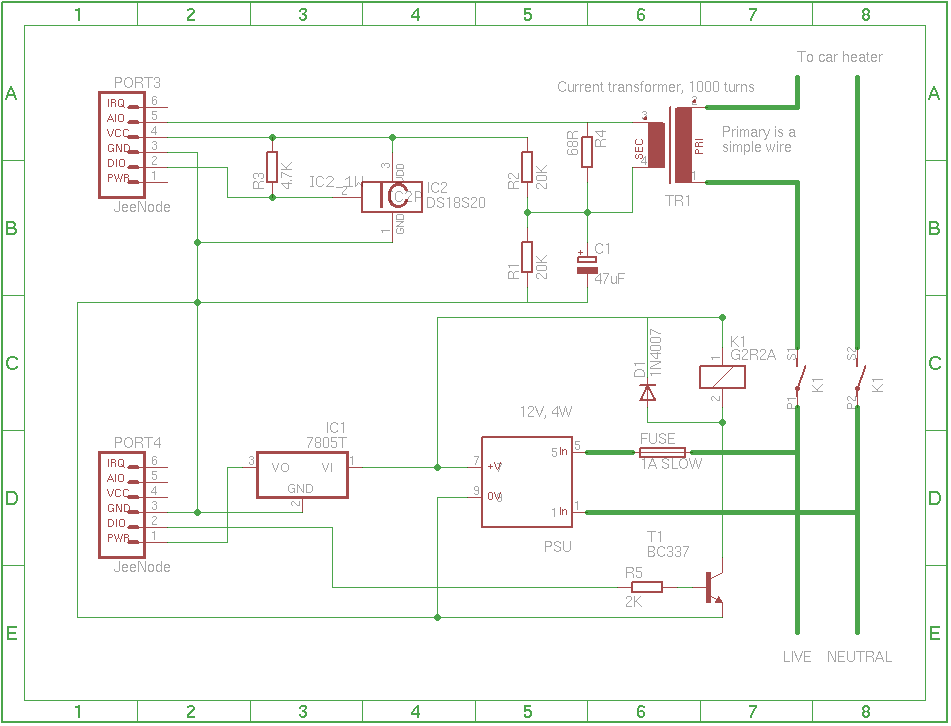
For my car heater controller I decided to use Alan Burlison's scheduler. I like it, because it leaves the main program file reasonnably short and allows to separate the code into multiple objects. I don't know if it makes the software more or less easy to write/maintain, but I find it fun to do it this way, and that's all that counts.
To implement 2-way communication between the JeeLink (master) and the JeeNode
(slave) using Jean-Claude Wippler's RF12 library, I created a Listener
object and a Speaker object that deal with receiving data and sending data
respectively, while the Protocol object implements the higher-level
protocol.
Here' how the slave's .pde file looks like. Notice how it contains only
definitions and a bit of initialization, but no big mess of code?
#define NB_ELEMENTS(a) sizeof(a) / sizeof(a[0])
Speaker speaker;
Protocol protocol(&speaker);
Listener listener(&protocol);
Task * tasks[] = { &listener, &speaker };
TaskScheduler scheduler(tasks, NB_ELEMENTS(tasks));
void setup() {
rf12_initialize(SLAVE_ID, RF12_868MHZ, HEATER_GROUP);
}
void loop() {
scheduler.run(); // infinite loop
}
Here's a sample of the slave's Listener.
class Listener: public Task { // Task from Alan Burlison's scheduler
public:
Listener(Protocol * protocol):
protocol(protocol)
{};
bool canRun(uint32_t now); // Taks's interface
void run(uint32_t now); // Task's interface
private:
Protocol * protocol; // higher-level protocol handler
uint8_t recv_buffer[BUFFER_LEN];
uint8_t recv_buffer_len;
};
bool Listener::canRun(uint32_t now) {
if (rf12_recvDone())
return (rf12_crc == 0 && rf12_len <= BUFFER_LEN);
return false;
}
void Listener::run(uint32_t now) {
recv_buffer_len = rf12_len;
memcpy((void *)recv_buffer, (void *)rf12_data, recv_buffer_len);
if (rf12_hdr == (RF12_HDR_CTL | (MASTER_ID & RF12_HDR_MASK)))
protocol->got_ack();
else {
if (RF12_WANTS_ACK) {
rf12_sendStart(RF12_ACK_REPLY, 0, 0);
rf12_sendWait(0);
}
protocol->handle(recv_buffer, recv_buffer_len);
}
}
And there's the slave's Speaker. Note that the Spaker tries to send data only
if its buffer_len is greater than zero. This prevents calling rf12_canSend()
when it's not necessary (according to the RF12 driver, you must not call
rf12_canSend() only if you intend to send data immediately after calling it).
When the Protocol wants to send something, it needs to get the Speaker's
buffer with get_buffer(), fill the buffer with data, and then call send().
Also, I implemented a retry mechanism in case no ACK has been received from
the master.
class Speaker: public Task { // Task from Alan Burlison's scheduler
public:
Speaker();
uint8_t* get_buffer();
void send(uint8_t len, bool ack);
void got_ack(); // called by the Protocol when it gets an ACK
bool canRun(uint32_t now); // Task interface
void run(uint32_t now); // Task interface
private:
uint8_t buffer[BUFFER_LEN];
uint8_t buffer_len;
bool with_ack;
uint8_t retry_count;
unsigned long next_retry_millis;
};
bool Speaker::canRun(uint32_t now) {
if (buffer_len > 0 && retry_count > 0
&& millis() > next_retry_millis)
return rf12_canSend();
return false;
}
void Speaker::run(uint32_t now) {
if (with_ack && retry_count == 1) {
buffer_len = 0;
}
uint8_t header = (with_ack ? RF12_HDR_ACK : 0)
| RF12_HDR_DST | MASTER_ID;
rf12_sendStart(header, buffer, buffer_len);
rf12_sendWait(0);
if (with_ack) {
retry_count – ;
next_retry_millis = millis() + SEND_RETRY_TIMEOUT;
}
else
buffer_len = 0;
}
void Speaker::send(uint8_t len, bool ack) {
with_ack = ack;
buffer_len = len;
retry_count = SEND_RETRY_COUNT + 1;
next_retry_millis = millis();
}
void Speaker::got_ack() {
buffer_len = 0;
}
The master's code is very similar, you can check it there.
[ Posté le 24 mars 2012 à 16:17 | pas de commentaire | lien permanent ]






























{kind=link}